Why Blob Storage Is Risky
Many people use Amazon S3 or equivalent services to replace their relational database data warehouses as blob storage coupled with technologies like the compressed-columnar parquet file format offers a reasonably performant, massively scalable and cheap alternative.
To understand why blob storage can be risky it is important to understand how Apache Spark executes writes to non-transactional storage systems like S3 or other blob storage. To do this we are going use a contrived example where every day a user extracts their bank account transactions to a CSV file named yyyy-MM-dd_transactions.csv:
| file | date | amount | description |
|---|---|---|---|
| 2019-08-04_transactions.csv | 2019-08-04 | 500.00 | Pay |
| 2019-08-04_transactions.csv | 2019-08-04 | -21.60 | Uber Eats |
| 2019-08-05_transactions.csv | 2019-08-05 | -55.29 | Uber Eats |
| 2019-08-05_transactions.csv | 2019-08-05 | -10.00 | Movie Ticket |
| 2019-08-06_transactions.csv | 2019-08-06 | -12.99 | Netflix |
| 2019-08-06_transactions.csv | 2019-08-06 | -20.00 | ATM Withdrawal |
After safely applying data types to the data the user wants to write that data as a Parquet file to Amazon S3 (provided by the hadoop-aws library) which is a non-transactional file system.
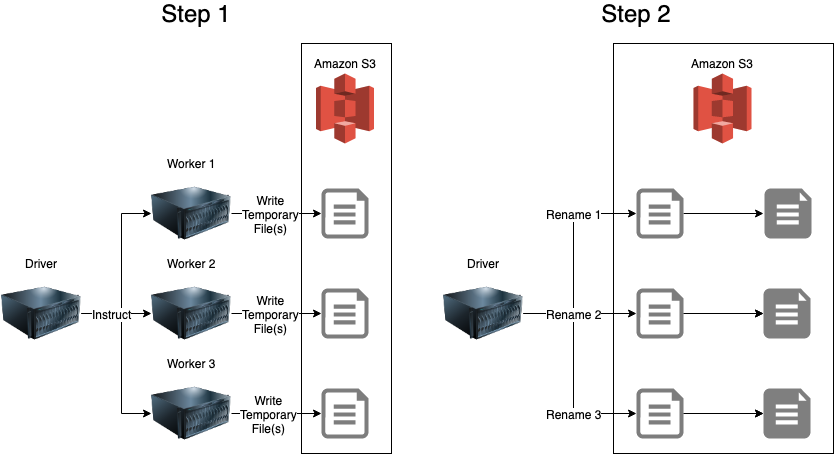
The actual process happens in two steps:
- The Spark
Driverprocess instructs theWorkerprocesses (in this case 3 workers) to calculate the dataset and write the partition(s) allocated to them to a_temporaryfile path on S3 and report success/failure to theDriver. Filenames include a UUID to likely avoid collisions. - Assuming all
Workerprocesses report success then theDriversequentially executes amv(move) for each temporary file part to move it into the final file path.
This is actually very risky due to the non-ACID properties of S3 (and other blob storage systems) as:
- The
mvmove process is executed by theDriverprocess is not Atomic (offers notransactionalguarantees) meaning that if the network connection is broken or theDriverprocess crashes partway through the list of files to move then the target path will contain a non-consistent dataset (only a subset of the data will have been moved). Contrast this to a traditional data warehouse withtransacitonalguarantees the database not commit the data if the connection was severed before a transactionCOMMIThas occured. - While the
mv(move) stage is occuring a consumer may read the data and receive a dataset with a non-consistent state as s3 does not provide read-Isolation. - The
mv(move) process is executed by theDriverprocess sequentially so it is anO(n)problem, meaning it will take longer and longer depending on the number of files to move, increasing the risk of the previousnon-consistentdataset issues.
Solutions
There are a few options to solve this problem:
Versioned Dataset
Write the full dataset out each run to a new path like: s3a://blob_store/transactions/${epoch}_transactions.parquet then on success update an external mechanism like the Hive Metastore to store the path to the dataset as latest (essentially the pattern described here).
This solution, whilst not terrible, comes with the drawback of:
- having to write a full dataset each time which is both inefficient and potentially costly
- having to run a seperate state store (database) to essentially hold pointers to the file path (S3 doesn’t support
symlinks) - how to know which version is most recent and/or valid without an external store (for consuming)
DeltaLake
DeltaLake is a custom and open source solution developed by Databricks which elegantly sidesteps the problem of not having transactional guarantees in S3 by using versioned _delta_log/index JSON files alongside the parquet to describe which changes (deltas) are required to move from one version of a dataset to the next. This has been included in Arc as the DeltaLakeExtract and DeltaLakeLoad plugin stages.
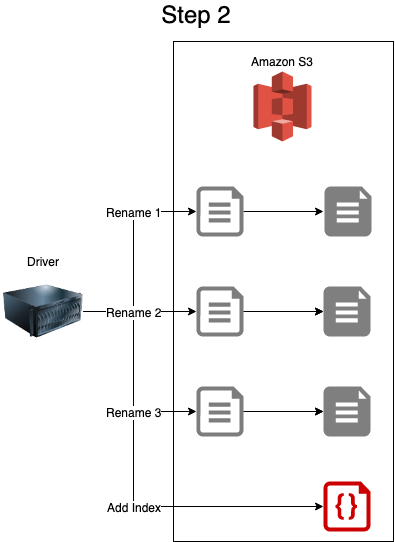
The actual process happens in three steps (very similar to the normal process):
- The Spark
Driverprocess instructs theWorkerprocesses (in this case 3 workers) to first calculate the dataset then write the partition allocated to them to a_temporaryparquetfile path on S3 and report success/failure to theDriver. - Assuming all
Workerprocesses report success then theDriversequentially executes amv(move) to each temporaryparquetfile part to move it into the correct file path. - Additionally the
Driverthen writes aJSONfile into the_delta_logdirectory to describe how to transition from onedatasetversion to the next.
To understand how the JSON pointer works here are the results at each day:
Running on 2019-08-04 produces the first version 00000000000000000000.json.
{"commitInfo":{"timestamp":1565327755045,"operation":"WRITE","operationParameters":{"mode":"Append","partitionBy":"[]"},"isBlindAppend":true}}
{"protocol":{"minReaderVersion":1,"minWriterVersion":2}}
{"metaData":{"id":"fb6b1664-1c2c-4b8e-b499-301960d4a1b7","format":{"provider":"parquet","options":{}},"schemaString":"{\"type\":\"struct\",\"fields\":[{\"name\":\"date\",\"type\":\"date\",\"nullable\":true,\"metadata\":{\"internal\":false,\"nullable\":true,\"description\":\"transaction date\"}},{\"name\":\"amount\",\"type\":\"decimal(10,2)\",\"nullable\":true,\"metadata\":{\"internal\":false,\"nullable\":true,\"description\":\"transaction amount\"}},{\"name\":\"description\",\"type\":\"string\",\"nullable\":true,\"metadata\":{\"internal\":false,\"nullable\":true,\"description\":\"transaction description\"}},{\"name\":\"_filename\",\"type\":\"string\",\"nullable\":true,\"metadata\":{\"internal\":true}},{\"name\":\"_index\",\"type\":\"integer\",\"nullable\":true,\"metadata\":{\"internal\":true}},{\"name\":\"_errors\",\"type\":{\"type\":\"array\",\"elementType\":{\"type\":\"struct\",\"fields\":[{\"name\":\"field\",\"type\":\"string\",\"nullable\":true,\"metadata\":{}},{\"name\":\"message\",\"type\":\"string\",\"nullable\":true,\"metadata\":{}}]},\"containsNull\":true},\"nullable\":true,\"metadata\":{\"internal\":true}}]}","partitionColumns":[],"configuration":{},"createdTime":1565327751167}}
{"add":{"path":"part-00000-c5bc4211-f1e5-447b-b6a6-2b06ac214421-c000.snappy.parquet","partitionValues":{},"size":2642,"modificationTime":1565327755000,"dataChange":true}}
The part-00000-c5bc4211-f1e5-447b-b6a6-2b06ac214421-c000.snappy.parquet would contain only:
| date | amount | description |
|---|---|---|
| 2019-08-04 | 500.00 | Pay |
| 2019-08-04 | -21.60 | Uber Eats |
Running on 2019-08-05 with saveMode=Append results in 00000000000000000001.json.
{"commitInfo":{"timestamp":1565327830447,"operation":"WRITE","operationParameters":{"mode":"Append","partitionBy":"[]"},"readVersion":0,"isBlindAppend":true}}
{"add":{"path":"part-00000-a173a6c3-09f5-443c-a378-b3270b2846da-c000.snappy.parquet","partitionValues":{},"size":2670,"modificationTime":1565327830000,"dataChange":true}}
The part-00000-a173a6c3-09f5-443c-a378-b3270b2846da-c000.snappy.parquet would contain only:
| date | amount | description |
|---|---|---|
| 2019-08-05 | -55.29 | Uber Eats |
| 2019-08-05 | -10.00 | Movie Ticket |
The important bit to focus on is the add operation which tells DeltaLake to add the data contained in part-00000-a173a6c3-09f5-443c-a378-b3270b2846da-c000.snappy.parquet to the previous version (0) which contains only part-00000-c5bc4211-f1e5-447b-b6a6-2b06ac214421-c000.snappy.parquet. On every 10th write DeltaLake will automatically capture a state snapshot so the maximum number of versions which need to be applied to the last known snapshot are limited. DeltaLake can also remove file parts from the dataset to compute the new state.
The beauty of this is that:
- as the
JSONindex is a single write it isatomic(S3 supported as it is singular) and cannot leave users reading an internally inconsistent dataset (isolation) as theJSONfile would not be written yet to instruct consumers to include those newparquetparts. - by default reading a
DeltaLakepath will return the most recent version. - the underlying data is just
parquetwhich has been well tested and offers excellent performance expected from compressed, columnar storage (and if required can be read directly as with any otherparquet). - users are able to ’time-travel’ back to previous versions without having to store full copies.
The only real limitation is that to get the full benefit the DeltaLake extract mechanism must be used but it has already been included in Arc as the DeltaLakeExtract stage.