Continues from Part 1.
4 Execution
4.1 The Pipeline
Now we have all the components of the pipeline ready all that is needed is to load them into the Spark ML Pipeline(). A pipeline helps with the sequencing of stages so that we can automate the pipeline in the image at the top of this post.
When Pipeline() is fit() to the training set it will call the fit() method of the two estimator stages (StringIndexer() and NaiveBayes() which will both produce models StringIndexerModel() and NaiveBayesModel() respectively) and transform() on all the rest of the stages. When the Pipeline() is called to transform() the test set it will call transform() on all the stages (including the models).
val pipeline = { new Pipeline()
.setStages(Array(regexTokenizer, remover, stemmer, ngram2, ngram3, removerHashingTF, ngram2HashingTF, ngram3HashingTF, assembler, labelIndexer, nb, labelConverter))
}
4.2 Pipeline Stage Parameters
Many of the stages in the pipeline take parameters, for example a key parameter in for the HashingTF transformer is .numFeatures(n). As we have multiple stages with potentially many parameters, and we don’t what the best parameters would be, what would be ideal is if we could test different parameters sets iteratively and see which set produces the best model.
The ParamGridBuilder() object allows us to easily build() an array of all the possible combinations of parameters we want to test:
// We use a ParamGridBuilder to construct a grid of parameters to search over.
// With 3 stages of hashingTF.numFeatures each with 2 values (1000,10000)
// this grid will have 3 x 2 = 6 parameter settings for CrossValidator to choose from.
val paramGrid = { new ParamGridBuilder()
.addGrid(removerHashingTF.numFeatures, Array(1000,10000))
.addGrid(ngram2HashingTF.numFeatures, Array(1000,10000))
.addGrid(ngram3HashingTF.numFeatures, Array(1000,10000))
.build()
}
Output:
Array({
hashingTF_2b4181ee161b-numFeatures: 1000,
hashingTF_410c0a05ff35-numFeatures: 1000,
hashingTF_e63a89fd73ba-numFeatures: 1000
}, {
hashingTF_2b4181ee161b-numFeatures: 10000,
hashingTF_410c0a05ff35-numFeatures: 1000,
hashingTF_e63a89fd73ba-numFeatures: 1000
}, {
hashingTF_2b4181ee161b-numFeatures: 1000,
hashingTF_410c0a05ff35-numFeatures: 10000,
hashingTF_e63a89fd73ba-numFeatures: 1000
}, {
hashingTF_2b4181ee161b-numFeatures: 10000,
hashingTF_410c0a05ff35-numFeatures: 10000,
hashingTF_e63a89fd73ba-numFeatures: 1000
}, {
hashingTF_2b4181ee161b-numFeatures: 1000,
hashingTF_410c0a05ff35-numFeatures: 1000,
hashingTF_e63a89fd73ba-numFeatures: 10000
}, {
hashingTF_2b4181ee161b-numFeatures: 10000,
hashingTF_410c0a05...
Now we need to pass our Pipeline() and the ParamGridBuilder() object to a CrossValidator(). The CrossValidator will execute the pipeline with each of the paramGrid parameters sets and test them using a MulticlassClassificationEvaluator() to determine the best model.
val cv = { new CrossValidator()
.setEstimator(pipeline)
.setEvaluator(new MulticlassClassificationEvaluator().setLabelCol("indexedLabel").setPredictionCol("prediction").setMetricName("precision"))
.setEstimatorParamMaps(paramGrid)
.setNumFolds(2) // Use 3+ in practice
}
To execute the model we call the CrossValidator().fit() method. After trying all combinations and comparing their results against a test set it will determine which is the best model. It is possible to get the model by calling cvModel.bestModel which then could be saved for future use.
val cvModel = cv.fit(training)
Once we have the model we are able to use it to transform a dataset which will append a column of predictions based on the parameter set in NaiveBayes().setPredictionCol().
val predictions = cvModel.transform(test)
5 Evaluating a Model
While it is very easy to write code to compare the predicted label to the input label of a dataset Spark ML provides a set of model Evaluators which can do the job for you:
// Select (prediction, true label) and compute test error
val evaluator = { new MulticlassClassificationEvaluator()
.setLabelCol("indexedLabel")
.setPredictionCol("prediction")
.setMetricName("precision")
}
val precision = evaluator.evaluate(predictions)
println("Test Error = " + (1.0 - precision))
If everything has run correctly you should see a result something like this:
Precision: Double = 0.44108
Test Error = 0.55892
Duration: 1893607 ms (~31 minutes)
That is only 44.1%! meaning if we were to use this model more than half my predictions would be incorrect. Here is a good explanation why:
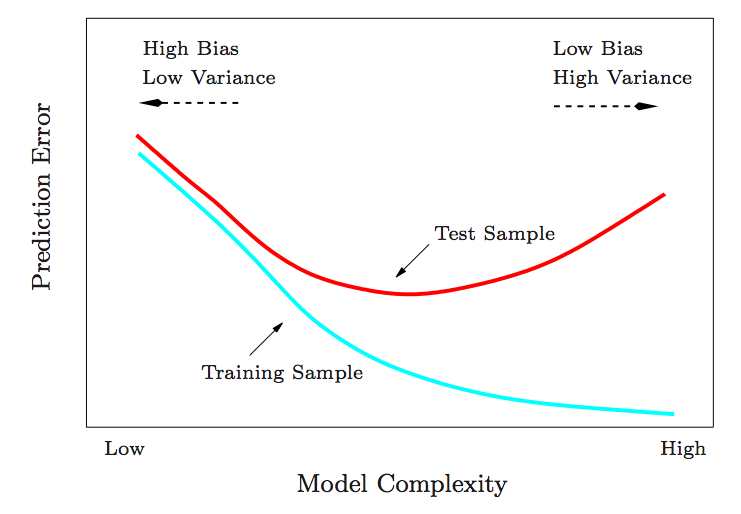
The problem is that we are trying to predict a very large and complex problem with a very small dataset of 20000 reviews for each label. We are running a low complexity model (due to small sample size) of a training sample which, based on the blue line, indicates that we will have a high rate of prediction error - which we observed with a 55.89% error rate.
5.1 Increase the training set
Once upon a time processing 100000 reviews would have been incredibly difficult due to lack of compute but with scalable architectures like Spark we should be able to process a much larger dataset. So let’s run the same code but increase the size of the input dataset to be one 10 times larger so we have 200000 reviews for each label. This should result in a more complex model and hopefully reduced prediction error:
Precision: Double = 0.468264
Test Error = 0.531736
Duration: 11918777 ms (~198 minutes)
So now we have gone from 44.1% to 46.8% accuracy and the time blew out from 31 mins to 198 mins (+538%). So we can see the effects of increasing sample size does roughly follow the blue line but at quite a large cost. Ideally I would like to run a much larger dataset through but I don’t have the resources. I am adding more CPU/RAM soon so that would hopefully allow larger training sets and hopefully a better model.
5.2 Reduce the labels
Another option would be to reduce the possible labels the model has to distinguish between whilst keeping the input dataset static.
We can do that in two ways, we either change the output options by trying to predict only 1 and 5 labels:
var reviewsDF = sqlContext.sql(
s"""
SELECT text, label, rowNumber FROM (
SELECT
reviews.overall AS label
,reviews.reviewText AS text
,row_number() OVER (PARTITION BY overall ORDER BY rand()) AS rowNumber
FROM reviews
WHERE reviews.overall IN (1,5)
) reviews
WHERE rowNumber <= $datasize
"""
)
+-----+-----+
|label|count|
+-----+-----+
| 1.0|20000|
| 5.0|20000|
+-----+-----+
or we can compress our label options by grouping certain labels:
var reviewsDF = sqlContext.sql(
s"""
SELECT text, label, rowNumber FROM (
SELECT
CASE
WHEN reviews.overall = 1 THEN 1
WHEN reviews.overall = 2 THEN 1
WHEN reviews.overall = 3 THEN 2
WHEN reviews.overall = 4 THEN 3
WHEN reviews.overall = 5 THEN 3
END AS label
,reviews.reviewText AS text
,row_number() OVER (PARTITION BY overall ORDER BY rand()) AS rowNumber
FROM reviews
) reviews
WHERE rowNumber <= $datasize
"""
)
+-----+-----+
|label|count|
+-----+-----+
| 1|40000|
| 2|20000|
| 3|40000|
+-----+-----+
Based on just the two label option 1 and 5 with the initial 20000/label dataset we get these results which are much better (87.52%) and with only 40000 reviews so we should still be able to get better results by increasing the training set size (where I managed to reach around 90.5%). This is expected we are taking the extreme reviews where we should see the largest discrepancies between reviews (it is unlikely that someone will use words like excellent or incredible in a review they give a score of 1 to).
Precision: Double = 0.8752
Test Error = 0.12480000000000002
Duration: 1155037 ms (~19 minutes)
Based on just the three label ‘flattened’ option with 1 2 3 with the initial 20000/label dataset we get these results which are also much better (65.88%) than the 44.10% baseline. I have tested larger datasets and manage to get > 70% accuracy with this method with larger data sets. In this approach we are normalising the good, bad or indifferent reviews where someone giving a 4 might use very similar language as a review with a score of 5.
Precision: Double = 0.65888
Test Error = 0.34112
Duration: 1897177 ms (~31 minutes)
At this point it makes sense to think about the use case of this data and what accuracy needs to be reached. One obvious approach would be to run as much of the 22 million reviews through the model and test as many parameter sets as possible (a brute force approach), perform additional feature extraction or switch to an alternative model to Naive Bayes.
5.3 What about overfitting?
The image above also shows a red line which gets better as the model gets more complex then actually performs worse as the model complexity reaches a certain level. This is an outcome of overfitting or building a model which fits the training data very well but doesn’t perform against actual test data.
You can imagine a very simple example of overfitting as:
- we need a model which predicts gender from height of person
- we accidentally set our training data to a set which only contains females
- we think we have an amazingly accurate model as it works 95% of the time on the training set
- the model actually performs very poorly when we expand the data to include both genders
Spark ML overcomes a lot of this problem by providing the ParamGridBuilder() and the CrossValidator() that we defined earlier:
val paramGrid = { new ParamGridBuilder()
.addGrid(removerHashingTF.numFeatures, Array(1000,10000))
.addGrid(ngram2HashingTF.numFeatures, Array(1000,10000))
.addGrid(ngram3HashingTF.numFeatures, Array(1000,10000))
.build()
}
val cv = { new CrossValidator()
.setEstimator(pipeline)
.setEvaluator(new MulticlassClassificationEvaluator().setLabelCol("indexedLabel").setPredictionCol("prediction").setMetricName("precision"))
.setEstimatorParamMaps(paramGrid)
.setNumFolds(2) // Use 3+ in practice
}
5.3.1 ParamGridBuider()
Based on how the HashingTF() transformer works we would expect that if we add more features we will get closer to a 1:1 word:hash ratio and surely having more features will help right?
Actually, no. Beyond a certain point adding features actually makes the model perform worse against the training data. My best performing basic model actually finds that 1000 3-gram features actually outperforms 10000 3-gram features due to overfitting.
How do I know?
We interrogate the CrossValidator().bestModel which is actually a PipelineModel. The only annoying thing is that we are finding the correct stage by using its index (stages(5), etc.).
val bestPipelineModel = cvModel.bestModel.asInstanceOf[PipelineModel]
val stages = bestPipelineModel.stages
val removerHashingTFStage = stages(5).asInstanceOf[HashingTF]
val ngram2HashingTFStage = stages(6).asInstanceOf[HashingTF]
val ngram3HashingTFStage = stages(7).asInstanceOf[HashingTF]
println("Best Model Parameters:")
println("removerHashingTF numFeatures = " + removerHashingTFStage.getNumFeatures)
println("ngram2HashingTFStage numFeatures = " + ngram2HashingTFStage.getNumFeatures)
println("ngram3HashingTFStage numFeatures = " + ngram3HashingTFStage.getNumFeatures)
Which produces:
Best Model Parameters:
removerHashingTF numFeatures = 10000
ngram2HashingTFStage numFeatures = 10000
ngram3HashingTFStage numFeatures = 1000
5.3.2 CrossValidator
The other useful feature to help prevent overfitting is CrossValidator().setNumFolds(n). Once again WikiPedia comes through with a good explaination but basically the number of folds is are the number of subsets the validator will create in your training data to limit overfitting.
So if we have .setNumFolds(2) the validator will perform these steps:
- randomly split the model into two equal subsets
- build all the models based on the
ParamGridBuilder()array on the first of two subsets of the training data and will test against the second subset - build all the models based on the
ParamGridBuilder()array on the second of the two subsets and test against the first subset - pick the model with the best fit across all of these runs and subsets
So you can see that if we set:
val paramGrid = { new ParamGridBuilder()
.addGrid(removerHashingTF.numFeatures, Array(1000,10000))
.addGrid(ngram2HashingTF.numFeatures, Array(1000,10000))
.addGrid(ngram3HashingTF.numFeatures, Array(1000,10000))
.build()
}
which results in 3x2 or 6 combinations and set the number of folds to the recommended minimum of 3:
.setNumFolds(3)
Find ourselves running the model trainer 18 times… which is the cost of limiting overfitting.
6 Next Steps
So we have built an end-to-end classifier based on Amazon book reviews and reached at best 90.5% accuracy and as low as 46%. The next best step would be to try a brute force attempt with a much larger training set and a very large list of parameters for each transformer.
I think I will try alternative classification algorithms (not NaiveBayes) but that is a topic for another post.