In my previous post I wrote some code to demonstrate how to go from the raw database extracts provided monthly by WikiPedia through to loading into Apache Spark GraphX and running PageRank.
In this post I will discuss my efforts to make that process more efficient which may be relevant to some of you trying to do proof-of-concept activities on less than ideal hardware. My test box (a standalone Intel Core i3-3217U (17W) with 16GB RAM and 60GB SSD storage) cannot complete the full graph build due to insufficient resources. At most I can process around 10-20% of the dataset before hitting these resource constraints.
To allow the process to complete, I have generated a ‘random’ subgraph of 2682475 vertices and 22751309 edges by altering the regex to extract just page_id and pl_from starting with 2:
val pagePattern = "\\(([2]\\d*),0,'([^,]*?)','.*?\\)+[,|;]".r
val pagelinksPattern = "\\(([2]\\d*),0,'([^,]*?)',0\\)+[,|;]".r
On the pagelinks side we will extract far more records than we initially need (77730564) because we do not validate whether the target appears in the pageRDD however these will be removed by the join() operation.
Running this with my previous code yields a quite consistent runtime using GZIP. This will be our benchmark for comparison.
Duration: 2132462 ms (~35 minutes)
Duration: 2110173 ms (~35 minutes)
1. Data Compression
I wanted to include some analysis on data compression as the results were surprising to me.
WikiPedia provides the extracts as GZIP files which can be read by the SparkContext.textFile() method out of the box. This is very useful as the pagelinks data set is 4.7GB GZIP compressed and over 35GB uncompressed. I do not have the luxury of that much disk space and even if I did I don’t really want to store all the raw data as it forces increased disk IO.
| Algorithm | Splittable | Compressed Size | Job Duration |
|---|---|---|---|
| GZIP | No | 5.78GB | 2132462 ms (~35 minutes) |
| BZIP2 | Yes | 4.78GB | 2926875 ms (~48 minutes) |
| Snappy | Yes* | 9.40GB | 1561278 ms (~26 minutes) |
| LZ4 | Yes | 9.19GB | DNF |
1.1. BZIP2
I have my Spark instance to utilise all 4 threads provided by my CPU (2 executors with 2 threads each). When running GZIP due to it’s non-splittable nature I can only see the job being executed as one task on one executor. When running the BZIP2 file which is splittable I can see four tasks being executed in parallel. I assumed that because I was allowing multi-threading the BZIP2 extract would be much faster but based on the result above it seems that the CPU overhead of the BZIP2 compression algorithm is so great that even multithreading cannot overcome it on my hardware.
1.2. Snappy
I also tested Snappy compression which you can see performed the best of the three but came with the painful process of building native libraries for snappy, hadoop-snappy and snappy-utils so that I could compress in the ‘correct’ hadoop-snappy format.
1.3. LZ4
I could not get LZ4 compression to work but I think it will be easier in later Spark releases. I think this could be a nice solution as it has comparable performance to Snappy but doesn’t have the confusion about snappy vs. hadoop-snappy and is already easily installed on most platforms by just a simple apt-get.
1.4. Having to recompress probably takes away these benefits
The other issue is that to do this testing I had to decompress the GZIP files and recompress as BZIP2 and Snappy. Both these processes take considerable time which is not included in my Job Duration above. By providing the files as GZIP WikiPedia has already contributed substantial CPU time which is not included in any of these job times.
2. Caching and Serialisation
One of the beautiful things about Spark is the ability to cache datasets in memory. If you think about the process described to calculate PageRank there are some very CPU intensive processes being carried out that we really don’t want to have to perform more than once:
- Data decompression
- Extracting data from each line by regex pattern matching
- Joining data
- Building the graph
Spark, by default, will cache objects in MEMORY_ONLY as deserialised Java objects so that these two commands do the same thing:
pageRDD.cache()
pageRDD.persist(org.apache.spark.storage.StorageLevel.MEMORY_ONLY)
Spark automatically monitors cache usage on each node and drops out old data partitions in a least-recently-used (LRU) fashion. This means that if we tell Spark to cache() our initial pageRDD dataset after it has been decompressed and done the regex pattern matching it will by default store it in memory as MEMORY_ONLY. This is great if we have enough RAM to store all the data we want to cache() but if we run big jobs we can quickly run out and the node will drop the ‘old’ (but possibly still relevant) data.
So what happens when our old dataset gets removed from RAM and we need it downstream? Spark recalculates it. This means that when I call the graph constructor and it generates a lot of additional cached RDDs it may flush out my original pageRDD and pagelinksRDD. In worst case Spark may have to go back and re-extract the data. As you can imagine this is a performance destroyer.
To avoid heavy recalculation an option is available to store datasets either spill to disk or use serialised datasets which take up less space in memory (which might allow you to store all the data in memory thus avoiding this problem) at the expense of increased CPU time or to allow the memory to spill to disk at the expense of disk IO and obviously lower access speed than RAM. The question is whether the cost of disk IO is less than the CPU cost of recalculation.
2.1. MEMORY_ONLY_SER
Spark suggests the first approach should be to try StorageLevel.MEMORY_ONLY_SER which will make the datasets much smaller and hopefully allow them to be kept in memory. The trade-off is that CPU time is spent serialising and deserialising the datasets.
pageRDD.persist(org.apache.spark.storage.StorageLevel.MEMORY_ONLY_SER)
pageRDD.count
With this code applied to the pageRdd, pagelinksRDD, edges and vertices RDDs I actually had worse performance by 8.2% which must be due to the overhead of serialising and deserialising the datasets.
pageRDD.persist(org.apache.spark.storage.StorageLevel.MEMORY_ONLY_SER)
pagelinksRDD.persist(org.apache.spark.storage.StorageLevel.MEMORY_ONLY_SER)
edges.persist(org.apache.spark.storage.StorageLevel.MEMORY_ONLY_SER)
vertices.persist(org.apache.spark.storage.StorageLevel.MEMORY_ONLY_SER)
Duration: 2307983 ms (~38 minutes) (108.2%)
2.2. MEMORY_AND_DISK
By watching the Storage tab in the application UI whilst the job is running I determined that the pagelinksRDD was not being stored in memory which meant heavy CPU time doing recalculation. My solution was to work out how I could cache as much as possible in RAM and spill over any additional data to disk which the MEMORY_AND_DISK option provides.
What is very nice about MEMORY_AND_DISK is that when the cache is full and more data is requested to be cached it actually spills those existing cached partitions to the disk as serialised objects - that means worst case upstream recalculations are not required. The downside of this is that there is CPU time spent serialising the objects being spilled to disk and also disk write time and storage requirements.
Here is a screenshot showing my datasets sitting partially in RAM and partially on disk: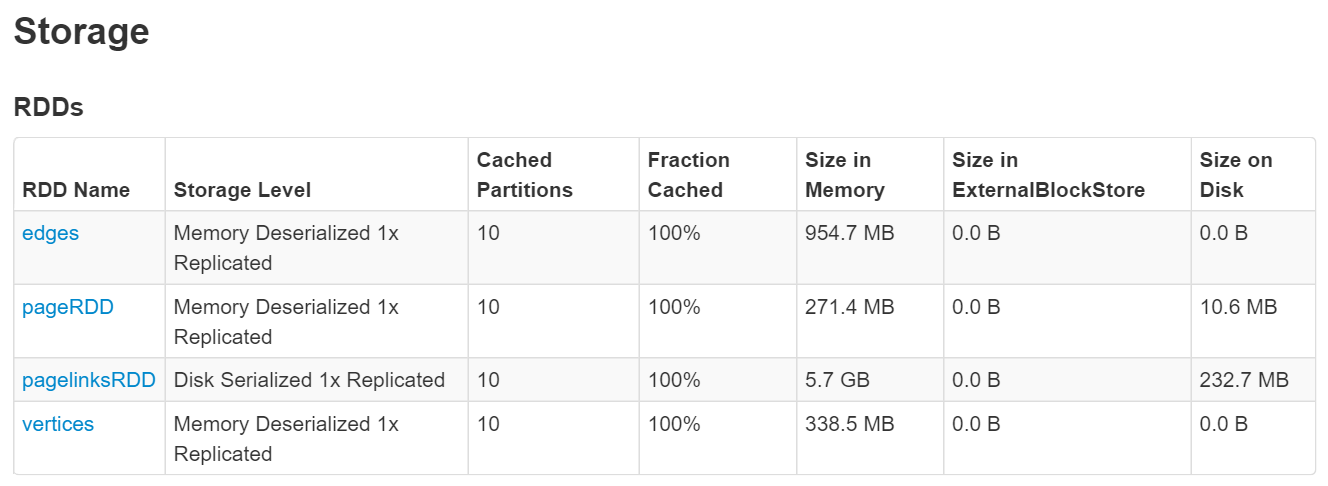
The best approach that I found was to determine from the program flow at which point those datasets would not be needed and manually unpersist() them:
pageRDD.persist(org.apache.spark.storage.StorageLevel.MEMORY_AND_DISK)
pagelinksRDD.persist(org.apache.spark.storage.StorageLevel.MEMORY_AND_DISK)
edges.persist(org.apache.spark.storage.StorageLevel.MEMORY_AND_DISK)
// after the pageRDD to pagelinksRDD join is done we don't need pagelinksRDD
pagelinksRDD.unpersist()
vertices.persist(org.apache.spark.storage.StorageLevel.MEMORY_AND_DISK)
// after the pageRDD to vertices mapping is done we don't need pageRDD
pageRDD.unpersist()
Duration: 2155781 ms (~35 minutes) (100%)
This approach is more scalable as it will utilise maximum available RAM and prevent recalculation assuming you have fast storage attached to the executors which is faster than recalculating the datasets.
2.3. partitionBy()
The final interesting thing I worked out was that due to the fact that Spark actually caches partitions not RDDs it may be beneficial to partitionBy() the datasets to cache as much as possible into RAM and spill any remaining data to disk. Because we are loading the GZIP files by default the pageRDD and pagelinksRDD will be single partitioned as Spark cannot store half a partition in RAM and half on disk.
To increase the number of partitions:
import org.apache.spark.HashPartitioner
val pageRDD: RDD[(String, Long)] = page.flatMap { line =>
val matches = pagePattern.findAllMatchIn(line).toArray
matches.map { d =>
// "page_title","page_id"
(d.group(2), d.group(1).toLong)
}
}.partitionBy(new HashPartitioner(10)).setName("pageRDD").persist(org.apache.spark.storage.StorageLevel.MEMORY_AND_DISK)
pageRDD.count
This means there will be 10 partitions in the pageRDD dataset which are derived by calculating a hash of the first field (page_title in this case). My understanding is that because we call HashPartitioner on both the pageRDD and pagelinksRDD that they will be partitioned by the same keys which should result in less shuffle operations for the join() stage resulting in improved performance - particularly when the larger datasets are considered. The partitioner does come with a downside of having to calculate the hash (again CPU bound) for each record which has resulted in decreased performance on my platform.
2.4. Best Performer: MEMORY_ONLY and MEMORY_AND_DISK
For me the best performance for my WikiPedia PageRank sub-graph was to do a hybrid of these approaches.
Ultimately my code behaved best on my subset of the WikiPedia graph without paritionBy() without allowing spill to disk on my two key datasets edges and vertices (and as the will be heavily used to create the graph they will not be evicted from memory).
pageRDD.persist(org.apache.spark.storage.StorageLevel.MEMORY_ONLY)
pagelinksRDD.persist(org.apache.spark.storage.StorageLevel.MEMORY_AND_DISK)
edges.persist(org.apache.spark.storage.StorageLevel.MEMORY_ONLY)
pagelinksRDD.unpersist()
vertices.persist(org.apache.spark.storage.StorageLevel.MEMORY_ONLY)
pageRDD.unpersist()
Duration: 1662171 ms (~27 minutes) (77.9%)
3. Summary
Hopefully if you have read this far this guide highlights one thing to you: there is no best way of optimising this for all architectures and you need to test these yourself in your environment with your data/code.