This post is about the brute-force reverse engineering of binary (compiled) programs using Large Language Models (LLMs) to automate this two-part problem: decompilation and conversion to a modern programming language.
This post covers the first part of the problem: decompilation.
Based on feedback I have split this article into two posts:
- The first (this post) describes the process of decompilation which can be skipped if you are already familiar with this topic.
- The second post describes the code-conversion and differential testing approach used to verify the conversion is equivalent to the original binary.
In this post an old Multi-user Dungeon (MUD) game binary has been targeted (see the reasoning below) but the approach applies equally well to other tasks, such as modernizing binaries or converting legacy COBOL to a modern language.
There are two reasons that LLMs should be good at this process, given their lineage:
- Summarization: Large Language Models tend to be extremely good at summarization where they are able to identify patterns across huge amounts of data. It is this skill that suggests, with a large enough context window, they should be able to identify patterns in decompiled code - perfect for identifying how variables and functions are used across a code base.
- Translation: Large Language Models evolved from Google Translate where they utilize neural machine translation to translate from one language to another (i.e. English to French). This suggests they should be capable of performing accurate ’neural’ translation of one programming language to another.
Ultimately this is a playground for me to learn about the real LLM capabilities (outside of standard benchmarks) where the journey is as interesting as the outcome.
Intro to MUDs
Back in the pre-internet days (yes, they existed) users would use a modem and their phoneline to connect to Bulletin board systems (BBS) where they could chat, transfer files and play games. These were a glimpse of the future where multiple ‘online’ users would be able to interact in real-time.
One of these BBS games was the extremely addictive MajorMUD - Realm of Legends: an online dungeons-and-dragons-esque fantasy game for the Worldgroup/MajorBBS platform. My friends and I were heavily invested in this game where - due to game balance design - the more time spent made your character more powerful and the game easier (our phone line was occupied for many hours). The game’s true strength was for groups of players to form parties and play the game together or against one another.

For all intents and purposes the source code has been lost and only a Windows 32-bit Dynamic-link library (DLL) remains. The GreaterMUD project was an independent ‘faithful rewrite’ but is also closed source. Therefore this 628KB DLL is perfect for doing brute-force reverse engineering via LLMs as we know the training process has not been compromised by ingesting this source code - so it can’t ‘cheat’ and replay memorized code.
Decompiling
From DLL to C?
Initially I tried to get the LLM to take raw assembly and try to rewrite the logic. This proved a dead end however I suspect if you had the resources you could easily generate a huge amount of training data compiling with different compilers/compiler options and train a very strong model. This is an almost ideal situation for LLM finetuning - a closed system with a known-correct outcome where you can mass-produce training data cheaply.
I tried multiple commercial decompilers before settling on Ghidra: an open-source decompiler built by the National Security Agency. It is extremely powerful and it is clear a huge amount of effort has gone into the pattern matching required for it to do a solid job of producing pseudo-C - that is their c like language that doesn’t directly compile.
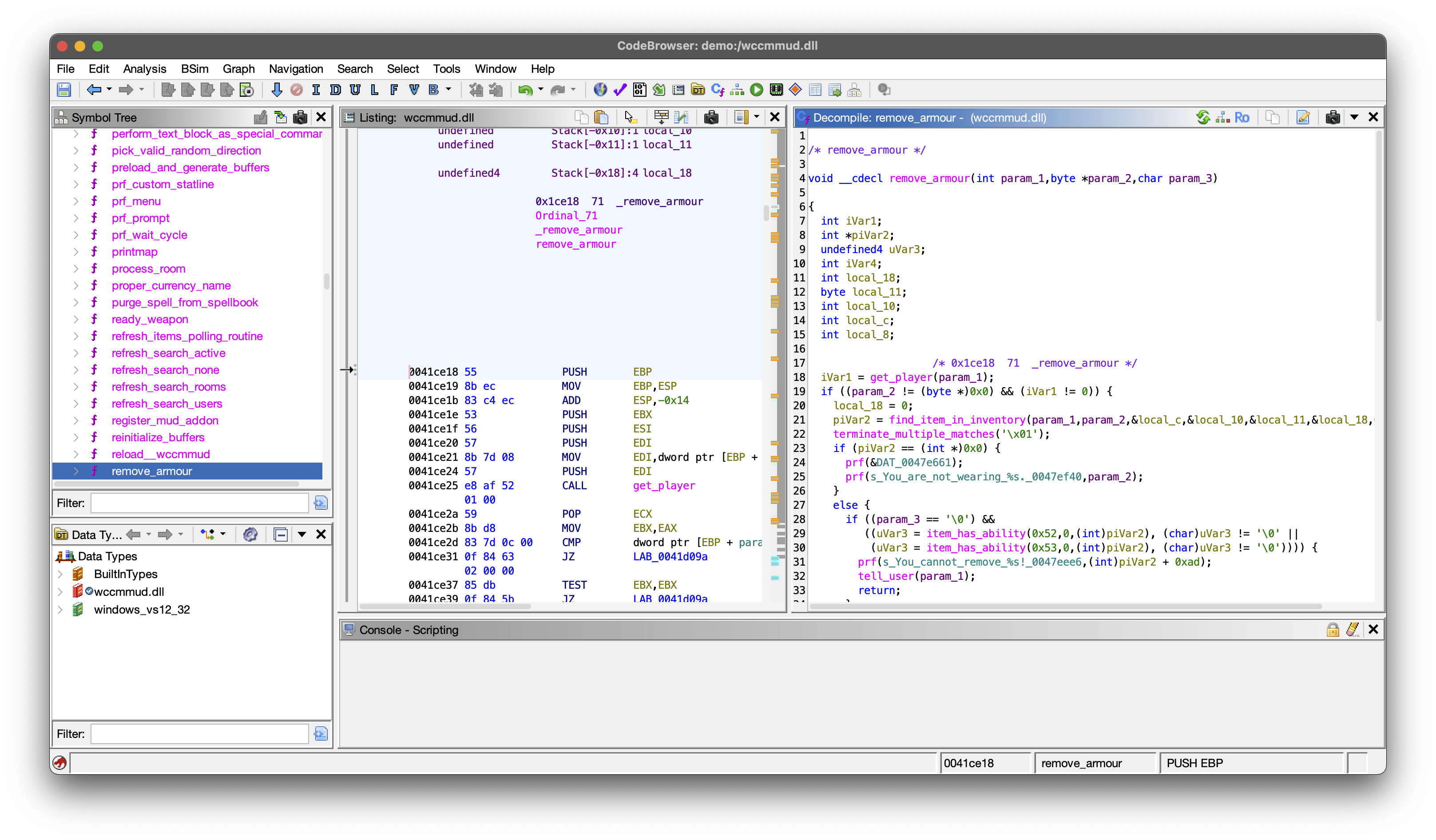
While its decompilation is amazing, depending on how the program has been compiled, a lot of information is lost in the process - like human-readable variable names (configuring the compiler to keep debug symbols in the binary would retain more of this information). So what you get is mostly logically-correct but not human-friendly code. Here is a randomly chosen (relatively short) function:
/* monster_add_cast_spell_to_user */
int __cdecl
monster_add_cast_spell_to_user
(int param_1,uint param_2,undefined2 param_3,int param_4,int param_5,int param_6,
char param_7)
{
int iVar1;
int iVar2;
int iVar3;
/* 0x25ea6 166 _monster_add_cast_spell_to_user */
iVar1 = get_player(param_1);
if ((iVar1 != 0) && (param_5 != 0)) {
iVar3 = -1;
iVar2 = 0;
do {
if (*(ushort *)(iVar1 + 0x40 + iVar2 * 2) == param_2) {
if ((param_7 != '\0') && (*(short *)(iVar1 + 0x54 + iVar2 * 2) < param_4)) {
*(short *)(iVar1 + 0x54 + iVar2 * 2) = (short)param_4;
*(undefined2 *)(iVar1 + 0x68 + iVar2 * 2) = param_3;
monster_display_spell_success(param_1,param_5,param_6,iVar1 + 0x1e,param_4);
return iVar2;
}
return -2;
}
if (*(short *)(iVar1 + 0x40 + iVar2 * 2) == 0) {
iVar3 = iVar2;
}
iVar2 = iVar2 + 1;
} while (iVar2 < 10);
if (iVar3 != -1) {
*(undefined2 *)(iVar1 + 0x40 + iVar3 * 2) = (undefined2)param_2;
*(undefined2 *)(iVar1 + 0x68 + iVar3 * 2) = param_3;
*(short *)(iVar1 + 0x54 + iVar3 * 2) = (short)param_4;
monster_display_spell_success(param_1,param_5,param_6,iVar1 + 0x1e,param_4);
return iVar3;
}
}
return -1;
}
How do you turn it into human-friendly code?
How do you identify that (iVar1 + 0x40 + iVar2 * 2) = (player_ptr->spell_ids[spell_slot_index] == _spell_id)?
Gemini enters the game …
Google’s Gemini models (specifically from flash-2.5 onwards with one million token usable context length) are absolutely amazing at crawling through code, identifying patterns and automating the task of renaming functions and variable names. gemini-cli supports tool calling so you can use a model-context protocol tool like GhidrAssistMCP to automate the this loop.
For clarity lets walk through an example loop:
Take a target function like
monster_add_cast_spell_to_userand use thedecompile_functiontool to retrieve the current state of Ghidra’s decompiled view of the function.Use the
function_xreftool to identify which functions have references tomonster_add_cast_spell_to_userand which functions are referenced frommonster_add_cast_spell_to_user. So, for example, you can see that in the source aboveget_player, andmonster_display_spell_successare referenced frommonster_add_cast_spell_to_user.Loop over the referenced functions and
decompile_functionto retreive their decompiled code.Let’s look at
get_player:/* get_player */ undefined4 __cdecl get_player(int param_1) { char *pcVar1; undefined4 uVar2; undefined *puVar3; int iVar4; /* 0x320d9 201 _get_player */ if ((param_1 <= *(int *)_nterms_exref) && (-1 < param_1)) { uVar2 = ptrblok(DAT_0048201c,param_1); return uVar2; } iVar4 = -1; if ((((*(int *)_usrnum_exref < 0) || (*(int *)_nterms_exref <= *(int *)_usrnum_exref)) || (*(int *)_usaptr_exref == 0)) || (*(int *)_usaptr_exref == 0)) { puVar3 = &DAT_00482aab; } else { puVar3 = *(undefined **)_usaptr_exref; } pcVar1 = (char *)spr(s_get_player:_%d(%d)_(usrnum:_%d_[_00482a86,param_1, *(undefined4 *)_nterms_exref,*(undefined4 *)_usrnum_exref,puVar3); internal_error(pcVar1,iVar4); return 0; }We can infer from the name
get_playerthat we are expecting this to take some sort ofplayer_idand return aplayer. What conclusions can we draw:uVar2 = ptrblok(DAT_0048201c,param_1); return uVar2;. This means the return value,uVar2, is theplayerand it is being assigned with theptrblok.- Without knowing anything except name
ptrblokwe can infer this is doing something to do with pointers that takesDAT_0048201cand the input argumentparam_1(but only if its less than or equal to_nterms_exref) and then returns theplayerresult - so its reasonable thatget_playertakes aplayer_idas the input parameter and it is used to index into some memory. You can also infer that_usrnum_exrefis some sort of maximum players value. - To be sure we can use
xreftool to see what is reading/writing toDAT_0048201c. Sure enough theallocate_buffersfunction has this lineDAT_0048201c = alcblok(*(undefined2 *)_nterms_exref,0x7ec);. - This is a goldmine. It says that
DAT_0048201cis an allocated memory region that contains contains_nterms_exrefentries ofplayerswhere each player is0x7ec(2028) bytes in size.
With our new knowledge by investigating
get_playerwe can now update themonster_add_cast_spell_to_userfunction:iVar1can be renamed toplayer_ptrandparam_1toplayer_idusing therename_symboltool.Now if you call
decompile_function(monster_add_cast_spell_to_user)again the source code will now returnplayer_ptr = get_player(player_id);in that line and, like your IDE, those variables will be renamed throughout the entire function so subsequent lines likeif (*(ushort *)(iVar1 + 0x40 + iVar2 * 2) == param_2)becomesif (*(ushort *)(player_ptr + 0x40 + iVar2 * 2) == param_2)and we immediately know we are doing some operation involving aplayer- hugely informative to make the next renaming decisions.
Now you can have gemini-cli run this in a loop and you can see how it will, over time, be able to “peel back the layers” of the original code and produce a more-and-more complete view of the code base.
This is the LLM party-trick #1: summarization of a huge amount of context - far exceeding the human brain’s capacity - to identify patterns.
structs and enums in Ghidra. GhidrAssistMCP has tools like the structs tool that will allow it to create and update data structures. Once correctly defined Ghidra will automatically update the decompiled code to show: player_ptr->spell_ids.Now the problem becomes one of just cost and time to produce: (note this is still in Ghidra pseudo-c)
/* Adds a cast spell effect to a player's active spell list. This function attempts to find an
existing spell by `spell_id`. If found and `can_overwrite_if_stronger` is true, the spell's
duration and value are updated if the new value is higher. Otherwise, it searches for an empty
spell slot to add the new spell. A success message is displayed to the player upon successful
spell addition or update. */
int __cdecl
monster_add_cast_spell_to_user
(int player_id,ushort spell_id,short duration,int value,spell *spell_ptr,
monster *monster_ptr,bool can_overwrite_if_stronger_flag)
{
player *player_ptr;
int spell_slot_index;
int empty_spell_slot_index;
undefined2 unused_stack_var;
/* 0x25ea6 166 _monster_add_cast_spell_to_user */
player_ptr = get_player(player_id);
if ((player_ptr != (player *)0x0) && (spell_ptr != (spell *)0x0)) {
empty_spell_slot_index = -1;
spell_slot_index = 0;
do {
if (player_ptr->spell_ids[spell_slot_index] == _spell_id) {
if ((can_overwrite_if_stronger_flag) && (player_ptr->spell_values[spell_slot_index] < value)
) {
player_ptr->spell_values[spell_slot_index] = (short)value;
player_ptr->spell_durations[spell_slot_index] = duration;
monster_display_spell_success
(player_id,spell_ptr,monster_ptr,player_ptr->given_name,(char *)value);
return spell_slot_index;
}
return -2;
}
if (player_ptr->spell_ids[spell_slot_index] == 0) {
empty_spell_slot_index = spell_slot_index;
}
spell_slot_index = spell_slot_index + 1;
} while (spell_slot_index < 10);
if (empty_spell_slot_index != -1) {
player_ptr->spell_ids[empty_spell_slot_index] = spell_id;
player_ptr->spell_durations[empty_spell_slot_index] = duration;
player_ptr->spell_values[empty_spell_slot_index] = (short)value;
monster_display_spell_success
(player_id,spell_ptr,monster_ptr,player_ptr->given_name,(char *)value);
return empty_spell_slot_index;
}
}
return -1;
}
A common question is: why bother with the tedious loop of renaming variables and defining structs in Ghidra? Why not just feed the raw, “ugly” pseudo-C directly into the LLM and ask for a translation?
The reason is rooted in how Transformers function. LLMs are trained primarily on open-source repositories (like GitHub) where code is written by humans, for humans. In that training data, variable names like player_ptr, spell_id, and is_active carry semantic weight.
When a model processes a token like player_ptr, it doesn’t just see a string of characters; that token influences the attention state of the model. It “primes” the LLM to expect patterns related to game logic, memory pointers, and entity management.
If you provide raw decompilation like iVar1 + 0x40, the model has to work purely on logical inference, which is prone to “hallucinated” logic. However, by providing player_ptr->spell_ids, you are giving the model a high-context anchor. This allows the LLM to leverage its vast statistical knowledge of how “players” and “spells” typically interact in code, leading to a much more accurate and idiomatic translation in the next step.
Part 2: Conversion
Now that we have a semi-human-friendly decompiled binary in pseudo-c, on to LLM party trick #2: translation and using it to convert this code to another language: Your binary is no longer safe: Conversion.